Pulp 3.2 Scale Testing to 27K Repositories and 173K Repository Versions
Updated: March 6, 2020 with correct worker count as 16, and additional resources in db section.
I recently did some Pulp3 scale testing, and I wanted to share the results along with how others
could reproduce them. I did this for pulp_ansible which
manages Ansible Role and Collection content and is compatible with the
ansible-galaxy command line.
Test Setup
A 16 CPU, 64 GB Ram Fedora 31 machine running on EC2 with pulpcore==3.2.0 and pulp_ansible==0.2.0b11.dev and had 16 workers. It was loaded with:
- 27,237 Repositories
- 173,311 Repository Versions, (6.36 repo versions per Repository on average)
- 10,000 CollectionVersions spread across 100 namespaces, 20 collection names each
- 51,816,410 content memberships. The number of units tracked uniquely in a RepositoryVersion
- Average of 1902 units per repository, spread over 6.36 repo versions on average
Deploying Pulp
I started 16 workers, one for each CPU. I installed Pulp to this Amazon machine using the Pulp 3 Ansible Installer. I used this config for 16 workers and pulp_ansible and the installer’s generic playbook.
Before running the installer, I:
- checked the keyless ssh access of my user, bmbouter
- verified my user’s passwordless sudo capabilities on the remote machine
- created an inventory file named:
~/devel/pulp3/inventorywith the IP of my host machine in it
I then installed Pulp using the following command:
ansible-playbook example-use/playbook.yml -u bmbouter -i ~/devel/pulp3/inventory
Test Workload
After creating all of this content (see how below), I ran a test workload on it which simulates adding a randomly selected CollectionVersion to a randomly selected 1000, 2000, 5000, 10000 repositories. The promotion workflow, is a two task workflow:
-
The first task selects an existing CollectionVersion randomly, and the N random Repositories also. This first task uses no locks.
-
The first task dispatches many subtasks each which handle a batch of N Repositories. These subtasks lock on the set of N Repositories meaning that other operations on any of the set of Repositories in the batch will not execute in parallel with other Pulp workloads.
Each batch’s set of Repositories are mutually exclusive with all other batches so these tasks are fully parallelizable with each other. This means the more workers a Pulp system has the workload should run faster and faster, assuming adequate hardware resources.
NOTE: Anytime we talk about Repository, we technically are talking about an
AnsibleRepository since Pulp repositories are typed.
Results
The measurement is for the completion of all tasks. I monitored this using the following command
with Django’s shell_plus command until it shows 0 tasks:
Task.objects.filter(Q(state='waiting') | Q(state='running')).count()
Here are the results:
| repo_count | batch size | num_tasks | run1 (s) | run2 (s) | run3 (s) | avg time (s) | avg repos / second |
|---|---|---|---|---|---|---|---|
| 1,000 | 63 | 16 | 34 | 34 | 34 | 34 | 29.4 repos / second |
| 2,000 | 125 | 16 | 63 | 63 | 63 | 63 | 31.7 repos / second |
| 5,000 | 157 | 32 | 150 | 151 | 154 | 151 | 33.1 repos / second |
| 10,000 | 157 | 64 | 310 | 318 | 326 | 318 | 31.4 repos / second |
batch size- The number of repositories handled per task.num_tasks- The number of tasks to be handled by the Pulp workers. Note the batch sizes are selected to generate a number of tasks that is divisible by 16, the number of workers this system has.run1- The amount of time in seconds the first run took to process all tasks.run2- The amount of time in seconds the second run took to process all tasks.run3- The amount of time in seconds the third run took to process all tasks.avg time- The average amount of time from the three runs.avg repos / second- The average amount of RepositoryVersions created per second.
Database and CPU Constrained
The system’s load falls mostly onto the DB and is CPU bound. All 16 workers of Pulp were engaged (as expected) and the postgresql processes auto-scales in terms of its processes, but it only has so many CPU cores to serve 16 independent connections (one from each Pulp worker).
Here’s a screenshot showing the postgresql processes heavily loading the CPU above 80% and 90% along with the rq Pulp worker processes submitting the SQL to PostgreSQL. I interpret the rate-limiting component to be the CPUs the database has access to.
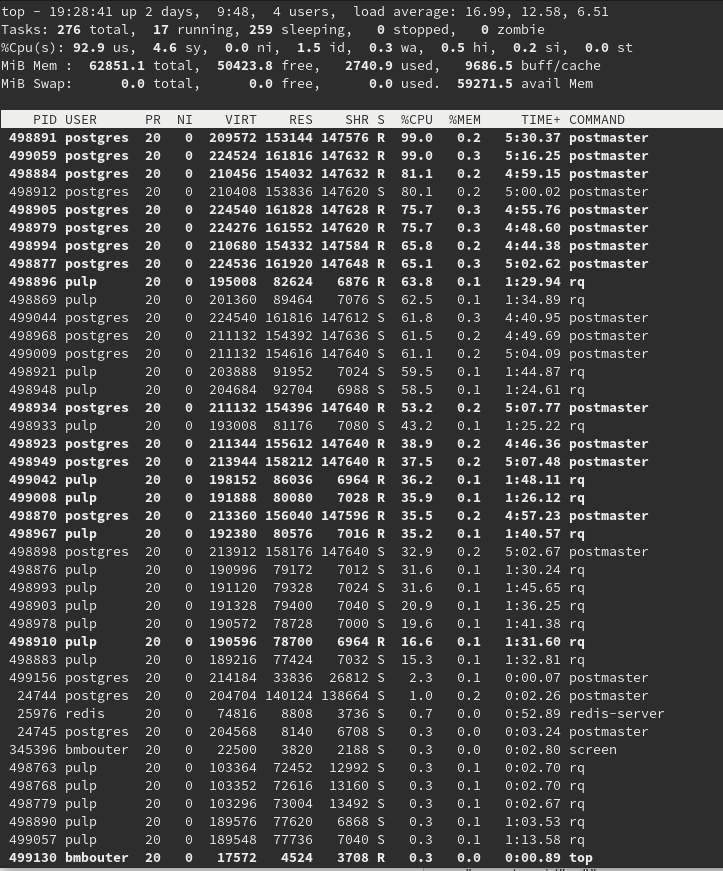
Database Query Analysis
I enabled auto_explain for postgresql
with these settings in my postgresql.conf:
session_preload_libraries = 'auto_explain'
auto_explain.log_min_duration = '1000ms'
auto_explain.log_analyze = 'true'
During promotion workflow testing, it shows slow queries like this one: https://explain.depesz.com/s/Wi2Q. Suggestions on how to improve this are welcome, but it’s overall a large database to query against. One unexpected part of the query plan is step #15 which perform a sequential scan against a table with an Index. After some discussion in #postgresql, other users there pointed out that the postgresql query plan is optimized and in some cases a Seq Scan is faster depending on the number of expected rows to be matched, e.g. 4950 in this case.
I confirmed the indexes were present, you can see the databases indexes present. Additionally a single query by pk on
core_content does show an INDEX SCAN to be used in the explain output.
Bigger Batches are Better
All tasks have to flow through the resource manager to provide the locking guarantees Pulp workloads require. This has a non-trivial overhead, and you can see that as the batch sizes get bigger throughput increases a little bit.
We should look at benchmarking the maximum task throughput of the resource manager in a separate blog post.
Horizontal Scaling would go Faster!
This system used 16 Pulp workers and so the work was divided over 16 parallel processes. If the DB has enough resources to keep up and Pulp had more cores it could start more workers and they could also run in parallel.
This means that those with more resources can scale up as much as their PostgreSQL cluster will. Also if you want to start a few workers Pulp will just work on the same workload over more time.
Based on all the runs in the table, an average rate of 31.4 RepositoryVersions created per second was observed. With 16 workers, that is 1.96 repositories per worker per second, or roughly 2 repositories per worker per second. To estimate the capability of your Pulp system with N workers, the expected number of repositories per second throughput is 2N. Note, you need another CPU core per worker at all times.
The Impact of RepositoryVersions
With each run more RepositoryVersions are created. Before the table was generated it was already 173,311. With each test run that number increased and for the 10,000 repo promotion test it was increasing 5% each time (roughly). This causes a non-negligible slowdown which you can see in the 10,000 repository row, with each test taking an additional 8 seconds.
Notes & Resources
To run this scale test I needed to develop some tools. I added these to pulp_ansible and documented them here.
Each of these commands dispatches commands into the Pulp tasking system. This is a convenient way to both have a direct connection to Pulp inside the task, but also to not have to write a custom multiprocessing deployment for such large workloads.
There are two halves to this implementation. There are dispatching commands which all use argparse so
you can inspect them for their options with -h, e.g. python generate_collections.py -h. Those
commands dispatch these tasks to Pulp workers which perform the workload. Below is a look at the commands
available.
Creating lots of Collection tarballs
This command created 10k collections in 29 min and 25 seconds. It dispatched 100 tasks to be handled by the 16 workers. It uses the shared filesystem as storage.
python generate_collections.py --num-namespaces 100 --collections-per-namespace 20 --versions-per-collection 5 --base-path "/var/lib/pulp/collections"
Fast loading lots of CollectionVersions into pulp_ansible
This command imported 10k collections in 32 min 52 sec. It dispatched 10000 tasks to be handled by the 16 workers. It reads from the shared filesystem as storage.
python fast_load_collections.py --collections-dir "/var/lib/pulp/collections/"
Create Repositories with RepsoitoryVersions and Collections
This command creates the Repositories, some number of RepositoryVersions for each Repository, and the percentage of CollectionVersion objects already in the system to associate with each RepositoryVersion. The command below creates 10000 repositories, with two RepositoryVersions per Repository. Each RepositoryVersion is expected to have 10% of all Collections in the system included so for the system with 10K collections, each RepositoryVersion would have 1000 CollectionVersions.
This command was started and stopped a lot, so I can’t report on its runtime.
python create_repos_with_collections.py --num-repos 10000 --num-repo-versions-per-repo 2 --collection-percentage 0.1
Running the promotion workflow
This command runs the test itself for either 1000, 2000, 5000, or 10000 Repository updates. These are handled by the 16 workers and the runtimes are in the table above.
python promote.py --repos-per-task 63 --num-repos-to-update 1000
python promote.py --repos-per-task 125 --num-repos-to-update 2000
python promote.py --repos-per-task 157 --num-repos-to-update 5000
python promote.py --repos-per-task 157 --num-repos-to-update 10000