Architecture¶
Pulp's architecture has three components to it: a REST API, a content serving application, and the tasking system. Each component can be horizontally scaled for both high availability and/or additional capacity for that part of the architecture.
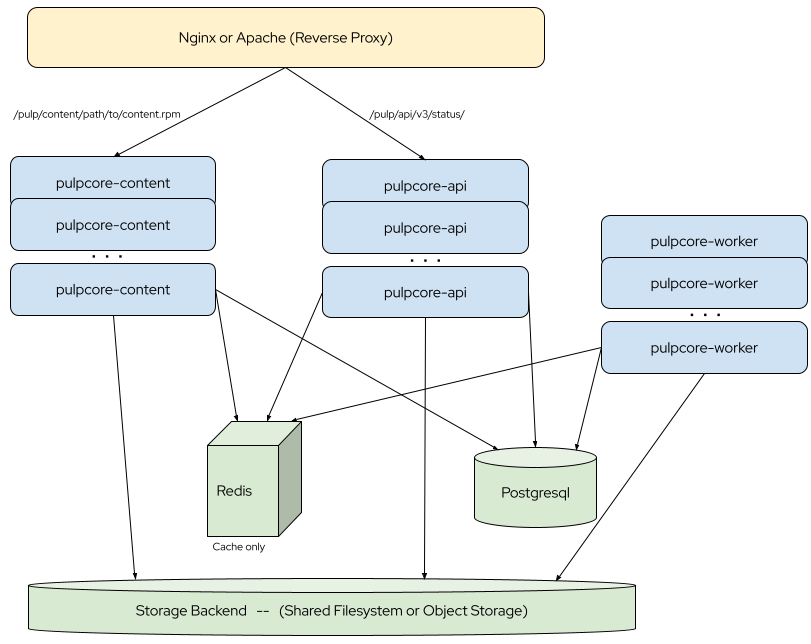
REST API¶
Pulp's REST API is a Django application that runs standalone using the gunicorn like
pulpcore-api entrypoint. It serves the following things:
- The REST API hosted at
/pulp/api/v3/ - The browse-able documentation at
/pulp/api/v3/docs/ - Any viewsets or views provided by plugins
- Static content used by Django, e.g. images used by the browse-able API. This is not Pulp content.
Note
A simple way to run the REST API as a standalone service is using the provided pulpcore-api
entrypoint. It is gunicorn based and provides many of its options.
API worker recycling
By default, pulpcore-api enables gunicorn --max-requests and --max-requests-jitter so
worker processes are periodically replaced. That limits memory growth from allocator
fragmentation in long-lived workers. Override via gunicorn's usual mechanisms (CLI flags,
GUNICORN_CMD_ARGS, or a config file). To disable recycling and keep unlimited worker
lifetime, pass --max-requests 0 on the pulpcore-api command line (gunicorn treats
0 as unlimited; Pulp only applies its own defaults when --max-requests was not passed
there). Disabling recycling is not recommended for production.
The REST API should only be deployed via the pulpcore-api entrypoint.
Content Serving Application¶
A currently aiohttp.server based application that serves content to clients. The content could
be Artifacts already downloaded and saved in Pulp, or
on-demand content units<on-demand content>. When serving
on-demand content units<on-demand content> the downloading also happens from within this
component as well.
Note
Pulp installs a script that lets you run the content serving app as a standalone service as
follows. This script accepts many gunicorn options.:
$ pulpcore-content
The content serving application should be deployed with pulpcore-content. See --help to see
available options.
Availability¶
Ensuring the REST API and the content server is healthy and alive:
- REST API: GET request to
${API_ROOT}api/v3/status/(see [API_ROOT](#)) - Content Server: HEAD request to
/pulp/content/orCONTENT_PATH_PREFIX
Distributed Tasking System¶
Pulp's tasking system consists of a single pulpcore-worker component consequently, and can be
scaled by increasing the number of worker processes to provide more concurrency. Each worker can
handle one task at a time, and idle workers will lookup waiting and ready tasks in a distributed
manner. If no ready tasks were found a worker enters a sleep state to be notified, once new tasks
are available or resources are released. Workers auto-name and are auto-discovered, so they can be
started and stopped without notifying Pulp.
Note
Pulp serializes tasks that are unsafe to run in parallel, e.g. a sync and publish operation on the same repo should not run in parallel. Generally tasks are serialized at the "resource" level, so if you start N workers you can process N repo sync/modify/publish operations concurrently.
All necessary information about tasks is stored in Pulp's Postgres database as a single source of
truth. In case your tasking system get's jammed, there is a guide to help (see debugging tasks).
Static Content¶
When browsing the REST API or the browsable documentation with a web browser, for a good experience, you'll need static content to be served.
In Development¶
If using the built-in Django webserver and your settings.yaml has DEBUG: True then static
content is automatically served for you.
In Production¶
Collect all of the static content into place using the collectstatic command. The
pulpcore-manager command is manage.py configured with the
DJANGO_SETTINGS_MODULE="pulpcore.app.settings". Run collectstatic as follows:
$ pulpcore-manager collectstatic
Analytics Collection¶
By default, Pulp installations post anonymous analytics data every 24 hours which is summarized on
https://analytics.pulpproject.org/ and aids in project decision making. This is enabled by
default but can be disabled by setting ANALYTICS=False in your settings.
Here is the list of exactly what is collected along with an example below:
- The version of Pulp components installed as well as the used PostgreSQL server
- The number of worker processes and number of hosts (not hostnames) those workers run on
- The number of content app processes and number of hosts (not hostnames) those content apps run on
- The number of certain RBAC related entities in the system (users, groups, domains, custom roles, custom access policies)
Note
We may add more analytics data points collected in the future. To keep our high standards for privacy protection, we have a rigorous approval process in place. You can see open proposals on https://github.com/pulp/analytics.pulpproject.org/issues. In doubt, reach out to us.
An example payload:
{
"systemId": "a6d91458-32e8-4528-b608-b2222ede994e",
"onlineContentApps": {
"processes": 2,
"hosts": 1
},
"onlineWorkers": {
"processes": 2,
"hosts": 1
},
"components": [{
"name": "core",
"version": "3.21.0"
}, {
"name": "file",
"version": "1.12.0"
}],
"postgresqlVersion": 90200
}
Telemetry Support¶
Pulp can produce telemetry data, like the response latency, using OpenTelemetry. You can read more about OpenTelemetry here. The telemetry is disabled by default.
Attention
This feature is provided as a tech preview and could change in backwards incompatible ways in the future.
In order to enable the telemetry, set OTEL_ENABLED=True in the settings file and follow the next
steps:
- Spin up a new instance of the Opentelemetry Collector.
- Configure the
OTEL_EXPORTER_OTLP_ENDPOINTenvironment variable to point to the address of the OpenTelemetry Collector instance (e.g.,http://otel-collector:4318). - Set the
OTEL_EXPORTER_OTLP_PROTOCOLenvironment variable tohttp/protobuf.
Pulp's telemetry is built on top of OpenTelemetry's standards, so it will respect its well-known
environment variables to configure it. For example, you can exclude some URLs from the telemetry by
setting the OTEL_PYTHON_EXCLUDED_URLS environment variable. For more details, please have a look
at the official OpenTelemetry Python documentation.
At the moment, the following data is recorded by Pulp:
- Latency of API endpoints (along with an HTTP method, URL, status code, and unique worker name).
- Latency of delivering requested packages (an HTTP method, status code, and unique worker name).
- Disk usage within a specific domain (total used disk space and the reference to a domain).
- The size of served artifacts (total count of served data and the reference to a domain).
The information above is sent to the collector in the form of metrics. Thus, the data is emitted either based on the user interaction with the system or on a regular basis. Consult OpenTelemetry Metrics to learn more.
By default, the API request duration uses the default bucket boundaries from the OpenTelemetry SDK.
It's possible to override it by setting a list of floats to the OTEL_PULP_API_HISTOGRAM_BUCKETS
setting. For example:
OTEL_PULP_API_HISTOGRAM_BUCKETS = [0.005, 0.01, 0.025, 0.05, 0.075, 0.1, 0.25, 0.5, 0.75, 1.0, 2.5, 5.0, 7.5, 10.0]